CH03_01. 탐색적 데이터 분석이란?
EDA? Exploratory Data Analysis로 데이터에서 분석에 필요한 여러가지 통계량을 계산하고,
시각화를 통해 이를 확인하는 작업을 의미한다.
- EDA는 분석을 하면서 데이터에서 확인하고 싶은 정보들을 찾아가는 과정이다.
- 정해진 규칙이 있는 것은 없고 분석가들의 분석 스타일, 어떤 데이터를 사용하느냐에 따라
분석 스타일과 프로세스가 바뀐다.
- 그래서 나만의 EDA process를 발견하는 것이 매우 중요하다.
CH03_02. Starbucks Survey
이번 수업을 통해서 스타벅스 고객들의 이벤트 관련 설문에 대한 응답 데이터를 활용하여
고객들이 이벤트에 대한 응답을 어떻게 하는지에 대해 찾고 고객 홍모 개선방안을 찾아본다.
1. 라이브러리, 데이터 로드를 한다.
form google.coalb import drive
drive.mount('/content/drive')
# starbucks customer data 폴더 안에 있는 데이터 3개 불러온다.
base_path = "/content/drive/MyDrive/Colab Notebooks/data/starbuck-customer-data/"
transcript = pd.read_csv(base_path + "transcript.csv").drop(columns = ["Unnamed:0"])
profile = pd.read_csv(base_path + "profile.csv").drop("Unnamed: 0 ", axis=1)
portfolio = pd.read_csv(base_path + "portfolio.csv").drop(columns = ["Unnamed:0"])
여기서 " .drop(columns = ["Unnamed:0"])" 이거와 "drop("Unnamed: 0 ", axis=1" 를 사용하는 이유는
아래의 그림과 같이 쓸데없는 컬럼을 지우기 위해서 사용한다.

+ 추가로 파이썬 drop 함수의 파라미터 중 하나인 axis에 대해 간략하게 설명한다.
index를 drop를 하려면 "axis = 0"으로 설정하고, 컬럼을 drop 하려면 "axis = 1"로 설정한다.
2. 데이터 전처리
데이터를 분석해보니 profile gender, incom 컬럼에서 결측치가 있다는 것을 발견했다.
이 결측치는 나중에 결과에 영향을 주기 때문에 전처리를 해주어야한다.

# 결측치를 포함하는 테이터들은 어떤 데이터들인지 확인한다.
profiel[profile.isnull().any(axis=1)]
이때 any(axis=1)의 의미는 컬럼에서 isnull 값을 갖는 데이터들을 모두 추출한다는 의미이다.

결과 값을 확인해보니 gender, income 컬럼에서 진짜 데이터가 없는 것으로 나왔고
다른 age, id 컬럼을 확인해보니 데이터가 있는 것으로 나왔다.
gender, income는 고객의 개인정보이므로 분석가가 스스로 데이터를 채워넣는 것은 어려기에
필요없는 데이터는 과감히 삭제하기로 하였다.
# 결측치 삭제
profile = profile.dropna()
profiel.info()

3. profile 데이터 분석
날짜 데이터(became_member_on)를 확인해보니 정수형으로 되어있다.
정수형으로 되어있으면 나중에 분석시에 어려움이 있으니 시간 정보로 변환해준다.


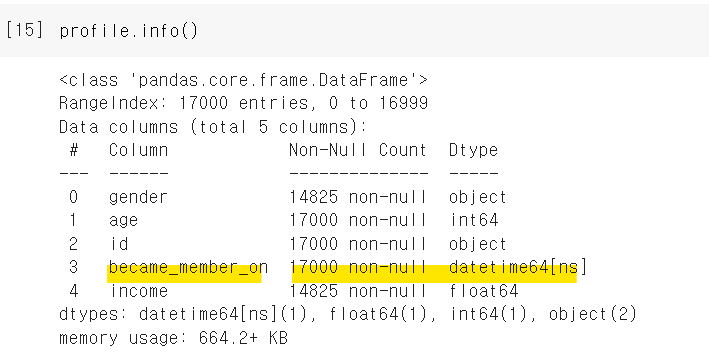
became_membero_on 컬럼이 datetime으로 바뀐 것을 확인할 수 있다.
■ 다음은 성별에 대한 분석이다.
plt.figure(figsize=(8,6))
sns.countplot(data=frofile, x="gender", palette="Set2")
plt.show()
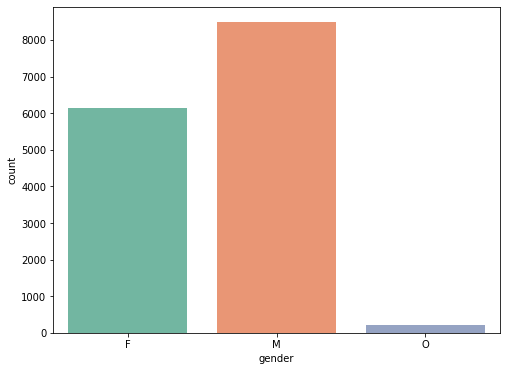
F : 여자, M : 남자, O : 남자도 아니고 여자도 아님.

뿐만 아니라 피벗 테이블을 사용하면 아래와 같은 결과값을 볼 수 있다.
pd.pivot_table(data=profile, index = "gender", values = "income")

■ 다음은 나이에 대한 분석이다.
plt.figure(figsize=(20,20))
sns.countplot(data=profile, x="age")
plt.show()

나이 분석 시 countplot를 사용하면 .... 위의 그림과 같이 끔직하게 그래프가 나오기 때문에
countplot 사용을 권장하지 않는다.
plt.figure(figsize=(20,20))
sns.histplot(data=profile, x="age", bins = 15, hue = "gender", multiple = "stack")
plt.show()

나이를 정확하게 파악하는 것도 중요하지만 얼마나 분포되어 있는지
확인하는 것이 분석 시에 더욱더 효율적이다.
pd.pivot_table(data=profile, index="gender",values=["age","income"])
성별에 따른 나이, 수익 평균을 확인할 수 있다.

■ 회원이 된 날짜에 대한 분석
profile["join_year"] = profile.became_mamber_on.dt.year
profile["join_month"] = profile.became_member_on.dt.month
profile
새로운 join_year, join_month 컬럼이 새로 만들어지고 년, 월의 데이터가 나타난 것을 확인할 수 있다.

join year 데이터를 활용하여 countplot를 그려본다.
sns.countplot(data=profile, x="join_year")
plt.show()

분석 결과 2017년도에 가장 많은 사람들이 회원이 된 것을 알 수 있다.
join month 데이터를 활용하여 countplot를 그려본다.
plt.figure(figsize=(12,8)
sns.barplot(x=x, y=y , order=x)
plt.show()

■ 수입에 대한 분석
plt.figure(figsize=(8,6))
sns.hisplot(data=profile, x="income", palette = "Set2", hue="gender")
plt.show()

■ profile 데이터에 대한 상관관계 분석
plt.figure(figsize=(6,6))
sns.heatmap(data=profile.corr(), square=True, annot=True)
plt.show()

4. transcript(실제 이벤트에 참여한 사람들에 대한 정보)에 대한 분석
plt.figure(figsize=(8,8))
sns.countplot(data=transcript, x= "event", palette="spring)
plt.show()

■ time에 대한 분석
pd.pivot_table(data=transcript, index = "event", values = "time)

transcript.time.value_counts()

plt.figure(figsize=(8,6))
sns.hisplot(data=transcript, x = "time")
plt.show()

offer received를 받았을 때 그래프가 훅 치솟는 것을 확인할 수 있었다.
CH03_03. Kaggle Survey
1. 라이브러리 5종세트 및 데이터 불러오기
form google.colab import drive
drive.mount('/content/drive')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
- csv 파일 불러오기
survey = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/data/kaggle_survey_2021_response.csv")
survey
2. 데이터 전처리
- 전처리하기 전에 csv 파일의 정보를 확인한다.
survey.info()

그러나 columns 의 갯수가 너무 많기 때문에 나중에 짤리고 한 눈에 알아보기 어렵다.
그러므로 필요한 갯수만 잘라서 확인한다.
survey.iloc[:, :15].info()
(iloc: 모든 로우에서 컬럼을 15개를 잘라달라는 의미이다.)

survey 정보에 대한 정보를 보면 Q7_Part_1부터 null 값이 있다는 것이다.
(즉, 다시 선다형의 질문이다. 이럴 경우에 dropna 함수를 활용하면 모든 정보 값이 없어지기에 사용하면 안된다.
뿐만 아니라 coulmn의 양이 너무 많아 전체적인 정보를 확인하기 어렵다.)
다시 필요한 부분만 잘라서 쓰기로 한다.
survey.iloc[:, :7] -> Q6컬럼까지만 잘랐다.
3. 한국사람 찾기
survey.Q3.value_counts() -> South Korea 359 라는 결과값을 확인할 수 있다.
survey.Q3.unique() -> 데이터 중 유니크한 값들만 찾아낼 수 있다.
survey[survey.Q3.str.contains("Korea")]["Q3"] -> 이렇게 사용하게 되면 "North Korea" 가 나올 수 있고
혹은 "South Korea"등 여러가지 조건들이 발생한다..
survey.loc[survey.Q3.str.contains("Korea"), "Q3"].unique()
-> array(['South Korea'], dtype=object) 모든 데이터 안에 "South Korea" 라는 값만 있다는 것을 확인할 수 있따.
■ 한국사람들을 불러와 본다.
korean = survey.loc[survey.Q3 == "South Korea". :] ("South Korea"데이터를 가지고 있는 모든 컬럼을 불러온다)
korean
■ 한국사람들의 성별에 대한 정보를 가지고 온다.
plt.figure(figsize = (8,6))
sns.countplot(data=koreas, x="Q2")
plt.show()

■ 최종학력에 대한 분석
plt.figure(figsize=(8,10))
sns.countplot(data=korean, y="Q4", palette="Set2")
plt.show()

4. 각 나라별 학력 통계 계산하기 ( * 이 부분 너무 어려움 ㅠㅠ)
countries = pd.pivot_table(data=survey, loc[1:, ["Q3","Q4"]], index="Q3", columns = "Q4", aggfunc={"Q4":"count"})
countries
■ 특정 국가 가져오기.
plt.figure(figsize=(6,12))
usa = countries.loc["United States of Ameria"]
canada = countries.loc["Canada"]
plt.subplot(2,2,1)
usa.plot(kind="barh")
plt.subplot(2,1,2)
canada.plot(kind="barh")
plt.show()

5. 프로그래밍 언어 선호도 분석 (* 점점 난이도가 높아져간다.. 이해하기가 어려워진다. 이 부분 다시 복습필요!)
Q7_columns = survey.columns[survey.columns.str.startswith("Q7")]
survey[Q7_columns]
■ 언어별 정보가 합쳐진 DataFrame 만들기
q7_list = []
for _, row in survey[Q7_columns][1:].iterrows():
q7_list.append(row[~row.isnull()].values) -> ~row.isnull() 의 의미는 isnull이 아닌 것을 뽑아 낸다는 말이다.
q7_list
survey["PL"] = ["PL"] + q7_listsurvey
■ 한국인 응답자의 데이터만 뽑아보기.
korean = survey.loc[survey.Q3 == "South Korea",["Q3"] + list(Q7_columns)]
korean
'혼자공부' 카테고리의 다른 글
| python - beautifulsoup 라이브러리 활용하여 웹크롤링하기! (2) | 2022.09.23 |
|---|---|
| 패스트캠퍼스) 빅데이터 분석 첫걸음 시작하기 : 파이썬 기초와 데이터분석 - 데이터 분석 라이브러리(2) - 학습일지 4주차 (0) | 2022.08.29 |
| 패스트캠퍼스) 빅데이터 분석 첫걸음 시작하기 : 파이썬 기초와 데이터분석 - 파이썬 프로그래밍(3) 학습일지 3주차 (1) | 2022.08.21 |
| 패스트캠퍼스) 빅데이터 분석 첫걸음 시작하기 : 데이터사이언스 기초_Machine Learning Workflow_학습일지 2주차 (0) | 2022.08.13 |
| 패스트캠퍼스) 빅데이터 분석 첫걸음 시작하기 : 데이터 분석 - 학습일지 1주차 (0) | 2022.08.08 |



